ACL 2020 Highlights: Interpretability, Evaluation and more.
This post discusses highlights of the main conference of the 2020 Annual Meeting of the Association for Computational Linguistics (ACL 2020). The conference accepted 779 papers with an acceptance rate of 22.7%, had 25 tracks along with demo sessions, virtual meetups and mentoring sessions.
For the first time ever, this year’s ACL conference has a special theme with a dedicated session and award: Taking Stock of Where We’ve Been and Where We’re Going. The theme surely highlights the current state of the field. Indeed, the NLP research community has been pushing boundaries in terms of performance (GLUE benchmark), innovative architectures (transformer, BERT & co), quick access to SOTA (HuggingFace’s transformers) and model sizes (GPT-3: 175B parameters). As declared by Clement Delangue, Co-Founder and CEO of HuggingFace: “NLP is going to be the most transformational tech of the decade!” But at this growth pace, ACL Program Co-Chairs deemed healthy for the research community to take a step back and reflect on the current state of the field, to avoid getting stuck in suboptimal solutions and consciously chart out the roadmap for future research directions.
In addition to the insightful theme choice, the Co-Chairs introduced 4 additional tracks including: Ethics and NLP & Interpretability and Analysis of Models for NLP. Indeed, after many sessions and workshops in the previous *CL events, the community is making it clear that responsible and ethical models are crucial as more NLP models are deployed in production and driving decisions that impact people’s lives. Moreover, as research works continue to push performance boundaries, interpreting and analysing models have become more relevant in order to understand the models inner mechanisms and learn about the secret ingredients for their performance.
We can see in the box-plot of views by area, sorted by median (credit: Yoav Goldberg) below, that the most popular tracks in ACL 2020 are (1) Interpretability and Analysis of Models for NLP, (2) Theme, (3) Cognitive Modeling and Psycholinguistics and (4) Ethics and NLP.
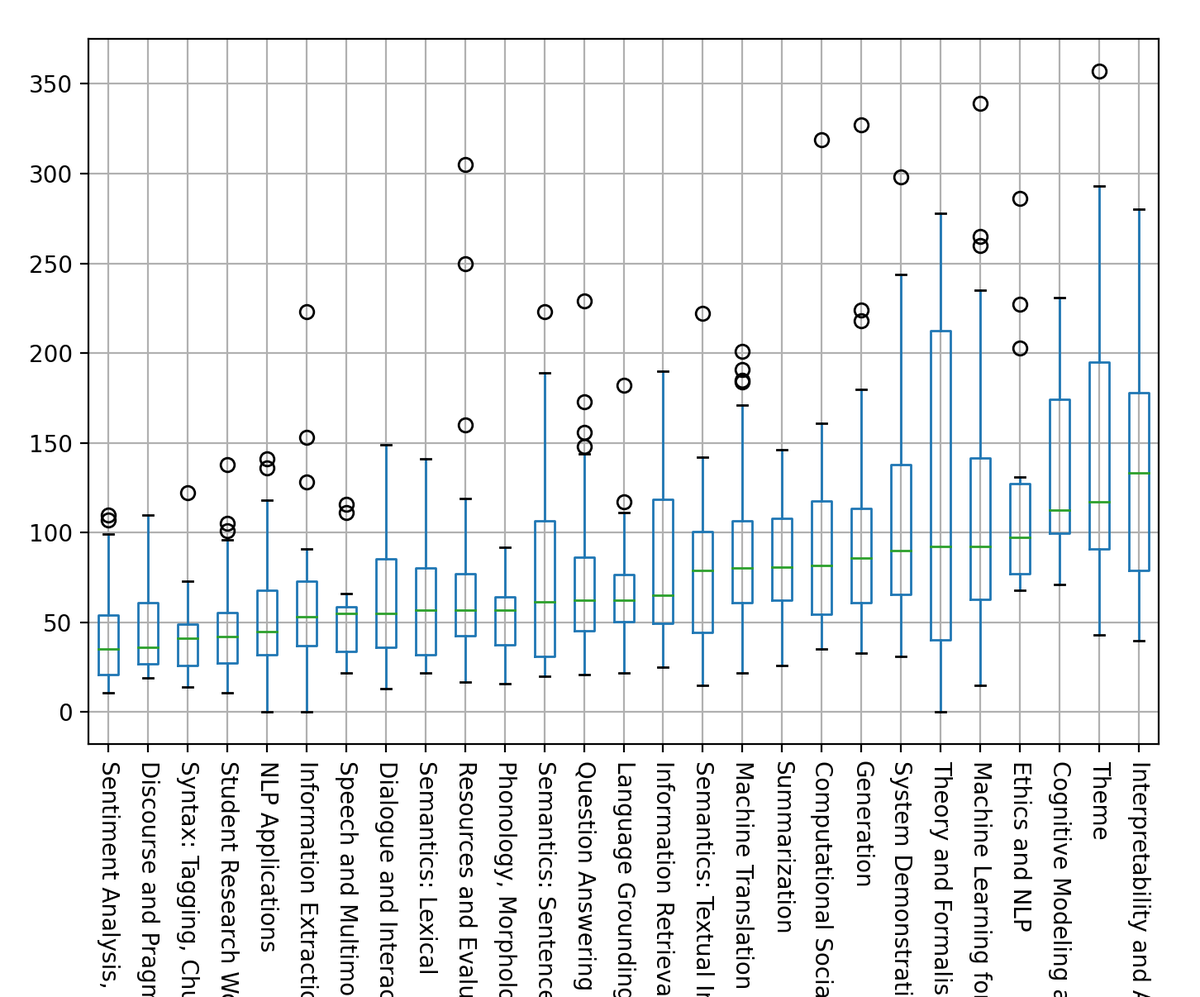
Note that the graph corresponds to a snapshot of the views on Jul 13, 2020. For readability, 3 outliers were removed with 416 (Linzen et al), 533 (Gururangan et al) and 970 (Bender and Koller) views.
Below are the topics on which I focused this year:
- Theme and Robust Evaluation
- Analysis and Interpretability
Theme and Robust Evaluation
The theme Taking Stock of Where We’ve Been and Where We’re Going illustrates the desire of the NLP community to make sure the current trend of training Machine Learning models to solve NLP problems, does not lead to a locally optimal state of the field’s progress. This takes us back to the 90s, when introducing statistical methods to computational linguistics raised discussions between protagonists from both sides claiming the advantages of each approach. But, this is still a very interesting approach, since taking this step back to reflect on what the community needs to tackle, should put it back on track to building more insightful and fair models. As a matter of fact, during the past year, we have seen a trend of training ever bigger transformers on ever bigger datasets to break benchmark leaderboards, in a metrics-obsessed approach to research. This trend comes with its costs, financial (training GPT-3 would cost $4.6M on a tesla V100 cloud instance), but also environmental and ethical. Indeed, so few groups have access to as much computational power and resources, which narrows the research competition. It also raises the question if bigger-is-better a scientific approach. To quote François Chollet: “Training ever bigger convnets and LSTMs on ever bigger datasets gets us closer to Strong AI – in the same sense that building taller towers gets us closer to the moon”. Though, it is agreed upon that these methods are the result of impressive engineering achievements, e.g. Turing-NLG is the result of developing DeepSpeed, a deep learning optimization library for distributed training. Moreover, they are promising methodologies for zero, one and few shots learning, which is useful for many NLP applications. Nonetheless, the community is clearly having an existential moment and doing some introspection to bypass this metrics-driven paradigm, in the quest to achieve human NLP ability in machines. Indeed, several talks argue that focusing on metrics drives us away from real linguistic challenges in the distribution’s tail and that models, though beat human performance with respect to metrics, are unable to handle trivial examples for the human mind. For instance, Bender and Koller show in their theme winning paper that meaning cannot be learnt from form. As a consequence, “the language modeling task, because it only uses form as training data, cannot in principle lead to learning of meaning”. They also shared a word of caution in their talk about using terms like “comprehension”, “understanding” and “meaning” when describing models capabilities.
Over the last few years, the main paradigm of many research papers has been to train large scale models and evaluate them on test sets that are similar to the training sets, leading many to believe that we are solving datasets not tasks. Indeed, in her keynote Kathy McKeown emphasizes that leaderboards are not always helpful to advance the field, because benchmarks capture the head of the distribution whereas the most challenging aspects are in its tail. The keynote goes through the present, past and future of the field as perceived by some of the most renowned NLP researchers. In particular, McKeown tries to depict the current state of the field being dominated by the achievements of deep neural networks. As a matter of fact, DNNs enable us to robustly solve many applications compared to other models and ensure a good performance using simpler models for tasks like machine translation, summarization and dialogue, making it simpler to deploy, build and democratize AI. Other researchers also praise the ingenuity of the attention mechanism and the success of generative models compared to n-gram approaches, in addition to the undeniable success of DNN in NLP benchmarks and representation learning. But, if we take a step back to the past of NLP to visualize the bigger picture, we find that the field used to rely extensively on looking at individual examples and little details. The evaluation used to be limited to manually examining outputs at a small scale and seek relevant conclusions in the distribution’s tail. Thus, McKeown puts the building blocks for the future by inviting the research community to focus on tasks that cannot be solved by deep learning or those for which we need to develop new methods. She also called for bringing data back to NLP by looking closely at examples, carefully analyzing them, and solving challenging problems that matter not just for which we have pre-built data sets. As for language generation, she points out that neural generators do not speak with purpose, say what they mean, choose words, form sentence structures intentionally or plan long text, like humans do. Finally, she concluded with the importance of the interdisciplinary parts of language, and advised that we should put more effort into the interpretability and analysis of outputs.
Along with the theme, evaluation is an important track in ACL 2020 with numerous thought-provoking papers. Many tackled the need to look at the data and analyze the errors when evaluating models. In her Lifetime Achievement Award speech, Bonnie Webber suggests that even something as trivial as looking at both precision and recall instead of F1 score can help in understanding the model’s weaknesses and strengths. In machine translation, for instance, it has been a common practice to compare machine outputs to human translations and calculate the BLEU score (dating back to 2002). However, in recent years, many works suggest the inadequacy of such a metric and call for more robust evaluation of machine translation systems. Mathur et al. highlight potential problems in the current best practices for assessing evaluation metrics and show that current methods are highly sensitive to the used translations. In addition, the overall best paper by Ribeiro et al. shows that while evaluating generalization via held-out test sets is useful, it has drawbacks including the overestimation of a model’s capability and the inability to determine its pain points. Thus, they propose a more comprehensive evaluation methodology which is model and task-agnostic, inspired from unit testing in software engineering and dubbed CheckList. The approach illustrates the behavioral testing principle of “decoupling testing from implementation” by treating the model as a black box, allowing the comparison of different models trained on different data sets. The authors also provide templates and other abstractions, allowing the users to generate a large number of test cases easily.
Analysis and Interpretability
Interpretability is absolutely essential to natural language processing, in order to understand models but also make applications more robust, fair and reliable. Indeed, the end-to-end fashion is predominant in language applications, requiring more efforts on accountability, trust, bias, and right to explanation. The Interpretability and Analysis in Neural NLP tutorial by Belinkov, Gehrmann and Pavlick gives an overview of the toolbox of interpretability. First, structural analysis suggests ways to understand what the model has learnt in its internal representations. The main approach is to use probing classifiers, which prove that a layer from a network trained to do a task A can predict a feature B. For example, A can be machine translation and B some linguistic features such as POS or morphological tags. Another idea is to change the activations so that the verb’s tense is changed, and afterwards measure the probability of predicting the pronouns he/she to check for gender bias. Although straightforward, these classifiers can be hard to evaluate, because there is no clear performance level for benchmarking, one can use SOTA or simply baselines. There is also recent work evaluating probing classifiers using code length, i.e. the number of bits to encode the probe. Another limitation of structural analysis can be the lack of causality or correlation between the probe and original model. As for behavioral analysis, they highlight tail phenomena through fine-grained checks and reward models that handle these hard exemples. This approach actually has a long history since the 90s, with ideas like designing test sets that are more adapted to ensure the model does not simply learn some artifacts. To do so, we can select test examples that are less likely to appear in train or simply replace words in sentences. The goal of this method is to make sure the models’ behavior is consistent with the examples they are given, and determine if the model fails in systematic ways. Besides, it is agnostic to the model’s structure and type since it focuses on creating challenge sets or probing sets, showcasing subject verb agreement, negation, antonyms, and other linguistic aspects. To design the challenge dataset, three methods are suggested. First, we can consider tight control by selecting pairs that are the same except for the phenomena we want to study, e.g. gender, negation or conjugation. Second, there is loose control by selecting many examples that illustrate a phenomena, then averaging on this set of interest. Third, we can choose adversarial examples with the objective of tricking the model. In addition, we can either construct these sets manually by having the models predict samples, then construct hard ones to trick it; or in a semi automatic fashion by filtering from an existing corpora, or in a complete automatic way. Nonetheless, these methods present limitations since they don’t determine if the models failure is due to its structure or the training data. Last but not least, there is visualization analysis, which allow us to understand the models, debug them, generate and test hypotheses about their behavior. However, these methods are harder to open source since they usually depend on the use case.
For the first time ever, ACL co-chairs introduced the “Interpretability and Analysis” track this year, yet it accepted an impressive number of 36 papers. Among these papers, a common observation is that looking at attention weights has gone out of fashion. In contrast, many works demonstrate that attention weights do not provide reliable explanations. For instance, Pruthi et al. cast doubt on attention’s reliability as a tool for auditing algorithms and proved that it can deceive humans into thinking that a model is unbiased with regards to gender even though it is biased. Besides, Sun et al. make the observation that some words receive higher attention weights whilst other relevant words don’t receive high weights and if attention weights are not so interpretable, this does not lead to bad performance. Other papers suggest approaches such as providing the training examples that influenced the prediction the most as an explanation. Han et al. mention that we usually use gradients, saliency maps, Lime or attention for explanations. They suggest using influence functions which are basically the product of saliency maps with the gradient, and show that these functions are consistent for NLI and sentiment analysis and help identifying artifacts in the training set. In addition, some papers include human users in the interpretability process. On the one hand, Hase and Bansal measure the effect of an explainability method as its effect on Simulatability: “A model is simulatable when users can predict its outputs”. They evaluate several explanation methods, such as feature importance, case-based and latent space traversal; and conclude that Lime is a good approach for tabular data. On the other hand, Chen et al. suggest a hierarchical explanation of a model’s predictions by splitting the sequence at the lowest point given a score measuring the words interactions. The method proves to be better than shapley and lime in terms of coherence between human predictions given explanations and the model’s predictions. They argue that the previous methods are token based, thus we need a higher level explanation. Moreover, faithfulness is an important aspect required in interpretability methods. Jacovi and Goldberg list the multiple attributes we would like in an interpretation: readability (easy to understand), plausibility (can convince us of the result) and faithfulness (accurately describe the true reasoning of the model). They note that there is clearly a trade-off between faithfulness and readability: NN activations are faithful but not readable. Furthermore, the authors offer three guidelines for faithful interpretations: (1) Faithfulness is not Plausibility, (2) Evaluating interpretation using human input is plausibility not faithfulness, and (3) Claims are just claims until tested. They also state a list of assumptions that prove the interpretations are not faithful. For example, if models predict the same output, they have the same reasoning process, if a model makes a similar decision, its reasoning is similar, and that certain parts of the input can be significant to the decision independently from other parts. Furthermore, Camburu et al. note that generated natural language explanations are not necessarily faithful, i.e. they are inconsistent with the actual reasoning process of the model. They introduce a sanity checking framework for models robustness against generating inconsistent explanations. The main idea consists in training a reverse model ExplainAndPredictAttention that, given an explanation, generates the hypothesis then gets the explanation and checks if it is consistent with the original explanation. Last but not least, DeYoung et al. introduce a benchmark to evaluate interpretable models, with the hope to measure the progress of the field. The tasks range from classification (sentiment, claim verification, conditional classification, entailment e-snli) to question answering (boolean QA, common sense questions - multiple choice); while the metrics focus on plausibility and faithfulness.
See also
- Selection of papers from ACL-2020 by Yacine Jernite (HuggingFace)
- Interpretability and Analysis of Models for NLP @ ACL 2020 by Carolin Lawrence
- Highlights of ACL 2020 by Vered Shwartz (AI2 & University of Washington)
- Ten emerging topics at ACL 2020 by NAVER LABS
- Knowledge Graphs in Natural Language Processing @ ACL 2020 by Michael Galkin
